
There was a time, back in the day, when life as a software architect was simple. Release cycles were measured in half-years and quarters. Application traffic was significant, but not insane. Data was always persisted in a centralized, relational database (because that was the only option). And best of all, the applications themselves were hosted on high-end, company-owned hardware managed by a separate operations team. Life back in the day was good.
But then the Internet kept growing.
Release cycles got shorter as the business fought to remain competitive. Traffic continued to grow and huge spikes could happen at any time. The relational database was coming apart at the seams, no matter how much iron was thrown at it. And in the midst of it all, everyone started talking incessantly about this new thing called “the cloud” that was supposed to fix everything. The brief period of easy living had come to end.
But let’s face it: What good architect wants easy living anyway?
A good software architect is driven by intellectual curiosity, and by that measure, now is a great time to be an architect. The technology options and design patterns available today are truly awesome, driven in large part by advances made in cloud-computing.
The Cloud Changes Everything
To fully understand the potential of cloud-computing, we need to look beyond merely migrating existing applications to the cloud and focus instead on what application architecture looks like for new applications born from inception in a cloud environment. The cloud is more than just a new place to park your application: it represents a fundamental paradigm shift in how we build software. Drafting a blueprint for cloud-born applications is obviously helpful for new, blue sky projects, but it benefits legacy, non-cloud applications too. By defining the ideal end-state for cloud-born applications, existing apps are given more than just a migration path to the cloud—they are given a clear path for how to be re-born in the cloud. Hallelujah.
But first let’s define what we mean by “the cloud” since the term is so terribly misused. (Former Oracle CEO Larry Ellison had a great rant on this topic during an interview at the Churchill Club.) When I use the term “cloud computing,” I mean something very specific: applications deployed on a hosting platform, like Amazon Web Services (AWS) or Microsoft Azure, that enables on-demand infrastructure provisioning and billing, in addition to a range of hosting-related services such as specialized storage and security. I don’t mean, as it is often used, anything that is available via HTTP. (It’s entertaining to see how Internet companies have recast themselves over the years to exploit the buzzword du jour, first as ASPs, then as SaaS providers and now as Cloud companies.) This narrower definition of “the cloud” also includes internally managed, highly virtualized data centers running cloud-provisioning software like VMware vCloud Automation Center (now vRealize Automation).
The special alchemy that cloud computing provides for software developers is that it turns hardware into software. It is difficult to overstate how profound this change is for software development. It means that infrastructure is now directly in our control. We can include infrastructure in our solutions, refractor it as we go and even check it into source control—all without ever leaving the comfort of our desks. No need to rack up a new server in the data center, just hop onto AWS Console and provision a couple of EC2 instances in-between meetings. (Or better yet, use an Elastic Load Balancer with an Auto Scaling Group to automatically provision the new servers for you while you drink Piña Coladas on the beach.)
This cloud-computing alchemy also means that cutting edge design patterns pioneered years ago by dotcom heavyweights like Amazon, Ebay and Netflix are now available to the masses. Indeed, many of the architectural considerations discussed here are not really new—they’re just now feasible for the rest of us. Cloud providers have virtualized hosting infrastructure, exposed infrastructure services through APIs, and developed on-demand billing, which means you can now experiment building crazy scalable architectures in your PJs at home. Very cool.
The Ten Commandments of Cloud-Born Application Architecture
Below are ten key tenets for architects to consider when developing applications in this new cloud-born world:
- There is No Silver Bullet
- Design for Failure
- Celebrate Database Diversity
- Embrace Eventual Consistency
- Move to Microservices
- Adopt Asynchronicity
- Automate Everything
- Design for Security
- Architect as Accountant
- Solving for Scalability Solves for Frequent Change
1. There is No Silver Bullet
First, the bad news. You don’t get extremely high scalability, availability and performance for free in the cloud using a virtual device “silver bullet” like a load balancer. You have to code it yourself. In the same way you have to build an application to be properly unit-testable (e.g. using dependency injection), you have to build your cloud application from the ground up to support scalability, availability and performance. How you do this depends on your business domain and requirements.
The good news is that a mature cloud platform gives you a whole bunch of infrastructure tools to work with to design around scalability, including things like CDNs, auto-scaling servers, NoSQL database clusters, load balancers, etc. The building blocks are at your fingertips, you just need to know how to use them. This means that cloud-era developers can no longer be mere coders, ignoring the underlying hardware. The hardware now is the software, so we have to be comfortable working in the world outside our IDE.
2. Design for Failure
Okay, now for the second piece of bad news: nodes fail all the time in the cloud. This is the dirty little secret of cloud computing. Anyone who has worked with AWS or Azure for any length of time knows that nodes go down on a weekly, and sometimes daily, basis. Server uptime for most cloud providers is actually worse than your own data center.
Worse? Come again?? Why would anyone switch to a hosting platform that provides worse uptime?
A very reasonable question. But now for some additional good news: node failures in the cloud are typically short-lived and less drastic than when something crashes in your data center. You rarely lose data or experience long periods of downtime when something fails in the cloud—as you might with a catastrophic failure of your own equipment. Put another way, the plethora of benefits that the cloud provides is so compelling, that it’s worth migrating to the cloud even with greater downtime.
And here is where the second tenet of cloud-born applications comes into play: you have to learn to embrace the unexpected and except failures as a normal part of daily life. Gone are the simpler days, when we worked on monolithic applications that used a single database. Back then, when something went wrong we could be pretty darn sure that something was really, really wrong. Rather than try to self-heal and keep going, we were happy if we could just raise an error to the end user. Why struggle to keep the application alive if the whole platform is in flames?

In the cloud, however, we have to design our applications so that they can handle frequent node failures (and even availability zone failures). And by so doing we also make our application more tolerant to failures in general. So the glass-half-full view of the regular node failures in the cloud is that they force us to write more robust apps. That may sound a little crazy, but consider this: Netflix actually develops services that purposefully shutdown nodes in production. Netflix’s Chaos Monkey (and its simian friends) are designed to wreak havoc in the production environment in order to ensure that developers are writing fault-tolerant code. Chaos Monkey makes sure that when a real failure happens, users keep getting movies streamed to their living room.
3. Celebrate Database Diversity
The days of homogenous data persistence (i.e. everything is stored in a centralized relational database) are over. This doesn’t mean that traditional RDBMS’s are dead (they’re not)—but it does means that the dictatorial reign of über normalized and meticulously structured relational data is at an end. The NoSQL umbrella of database technologies, which covers document databases, network databases, and key-value stores, among others, have emerged as industrial strength alternatives to RDBM’s, offering big advantages for many use cases.
One of the drivers for this shift toward heterogeneity in data persistence is the realization that the classic ACID principles (Atomicity, Consistency, Isolation and Durability) that underlie the relational database transaction engine severely limit scalability and are overkill in many situations. In 2000, Eric Brewer presented the CAP Theorem in a talk at the Symposium on Principles of Distributed Computing. The CAP Theorem states that in distributed systems, you can only guarantee two of the following: Consistency, Availability and Partition Tolerance. ACID-based relational databases choose Consistency and Partitioning, which means they can’t guarantee Availability. That is to say, ACID databases will fail before they return inconsistent data or if active nodes in the database cluster can no longer communicate with each other.
In many situations, however, Availability is far more important than Consistency or Partition Tolerance. For example, it may be totally fine if the information on a product detail page for an e-commerce site is out of sync between nodes in a cluster for a few minutes (i.e. lack of Consistency) but it’s completely unacceptable if those pages are down for anytime at all (i.e. Availability) because money will be lost if people can’t shop. Loosening the grip of relational database’s ACID monopoly allows us to optimize for these other use cases. The cloud makes this much easier by giving us the ability to quickly spin up and cluster NoSQL database nodes that provide ACID alternatives.
4. Embrace Eventual Consistency
For those developers who have only ever lived under ACID rule, life in a data democracy can be a little scary. How do I cope with data that is inconsistent? What’s the impact of working without transactions? What actually happens when data is out of sync between nodes? Fortunately for us, eBay’s Dan Pritchett established an alternative to ACID called BASE (Basic Availability, Soft-state, Eventual consistency) which gives developers a clever and comforting new four-letter acronym to guide them. The idea behind BASE is that there are a host of design patterns that enable functionally correct systems even when data is not consistent 100% of the time. In a BASE-oriented system (think of ACID and BASE as two ends of a spectrum), it’s okay if data gets out of sync between nodes, as long as it is consistent eventually. A message queue, for example, can be used in lieu of a transactional two-phase commit in most situations where multiple updates are used to execute a single logical operation, and thus the data will be updated eventually but not necessarily immediately. Making the update statements idempotent (which means they can be repeated multiple times and still produce the same result), further improves fault tolerance by making operations less fragile to retries.
Once we embrace eventually consistency, a universe of options open up to help us design for scalability and availability. (Amazon CTO Werner Vogels wrote a seminal article on eventual consistency that further explores this.) For starters, eventual consistency means that my application can keep moving even if some of my database nodes are down. Additionally, it makes it easier to de-normalize data and distributed it across different databases. Once I’m cool with the idea that my related data may be a little out-of-sync across nodes, I can shed my relational database foreign keys and the ACID constraints it imposes. Even allowing a very short window of time when nodes are allowed to be out of sync can be a powerful tool. For example, one of the teams at POP made significant performance gains on a heavily trafficked e-commerce ticketing site by simply allowing some of the volatile availability data to be cached for just one minute. This took a huge load off the database, and, in practice, didn’t cause too many headaches for end users. For the handful of times when a conflict did arise, it could be handled in other ways in the checkout path.
It is worth noting that ACID is not in inherently bad. Some data needs Consistency over Availability and Partitioning. But in practice, this is a small percentage of data. Just choose carefully and keep an open mind when selecting your data persistence choice.
5. Move to Microservices
Cloud computing also makes implementing microservices much easier. Microservices essentially represent the next evolution of Service Oriented Architecture (although SOA is so vaguely defined it’s impossible to tell exactly how it relates to microservices). Whereas SOA is generally concerned with using web services (initially, via SOAP) to separate application layers (e.g. front-end, business logic, data), microservices are typically focused on segmenting components within layers via REST. In a cloud-app, after we embrace eventual consistency and data heterogeneity, we can promote greater fault tolerance by decomposing course-grain functionality into completely separate RESTful web services, running on their own nodes with their own databases.
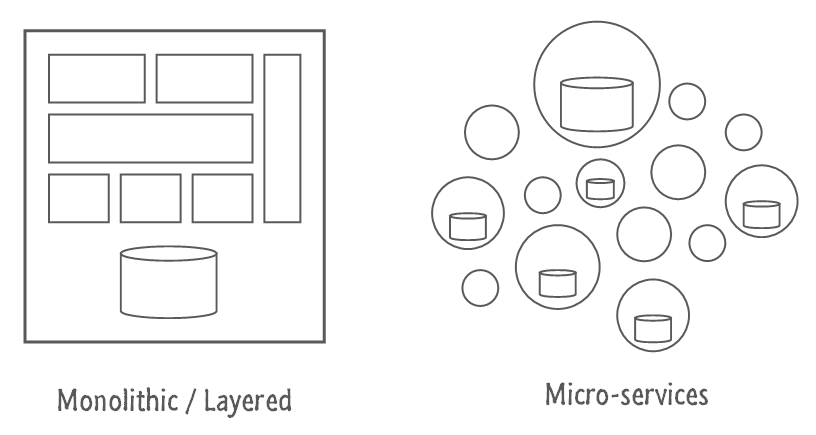
Microservices take the best practice of separation of concerns to the next level by encapsulating functional components (e.g. authentication, product information, inventory, checkout, user management, etc.) into different web services, which can then be deployed on a different set of nodes. This enables the development of much more robust architectures because apps can be designed to keep moving forward even if some of the services are down.
Microservices also help promote organizational scalability. Gilt.com migrated toward a microservice architecture initially for scalability, but then realized it was a powerful way of organizing development teams. Giving a small dev team end-to-end ownership and responsibility for a single stand-alone web-service offered several organizational advantages: (1) it increased overall quality (the developers get paged when the service goes down, so they are incentivized to make it robust), (2) it made it easier for developers to understand the overall architecture of the application, and (3) it reduced the amount of code that a dev team had to deeply understand themselves.
6. Adopt Asynchronicity
Once you start developing an application in the cloud using the principles outlined above, it becomes imperative that you embrace a highly asynchronous architecture as well. There are three main reasons for this. First, by moving away from a monolithic architecture toward a microservices-based model, it means you will be replacing in-process method calls with out-of-process API calls. This introduces more latency which can negatively affect performance. However, you can minimize these performance issues by replacing standard blocking request/response calls with non-blocking, asynchronous calls to allow the page or service to keeping moving while the REST calls run in the background. This approach naturally leads toward an event-driven model which promotes fault-tolerance and better performance.
The second reason it’s critical to embrace an asynchronous approach in a cloud application is that you can’t achieve true fault tolerance if your code is written in a sequential manner. That is, segmenting functionality into separate microservices running on separate nodes doesn’t make your application more robust if the calling code always hangs when it tries to call a faulty microservice. Instead, you want to move away from a blocking request/response model toward an asynchronous, message-oriented model, so that the page or service can complete the rest of the work, even if it encounters some broken services along the way.
The third reason why asynchronicity makes sense in the cloud is that it helps support eventual consistency. With eventual consistency, nodes may not all get updated at the same time as part of an ACID transaction. Instead, they may get updated later via message queues or other background processes. By designing your application to support regular asynchronous communication, you will also make it easier to implement the non-sequential data updates that occur in an eventually consistent system.
It is worth noting that this type of message-oriented, fault-tolerant application is commonly referred to as a Reactive System. Reactive Systems are responsive, resilient, elastic and message-driven. The Reactive Manifesto is the best articulation of this philosophy. And while Reactive Systems are not necessarily cloud-based systems, in practice, it’s much easier to implement a Reactive System in a cloud-based environment, so practically speaking they’re similar beasts.
7. Automate Everything
In the cloud, hardware becomes software and infrastructure can be manipulated through a rich set of APIs. This opens up a new universe of possibilities for DevOps. Entire platforms can be spun up and decommissioned automatically—and you only pay for the slice of time it is running. This reduces one of the barriers commonly faced in Continuous Delivery: setting up and maintaining appropriate staging/production environments. By maintaining infrastructure deployment scripts in source control and automating the creation of the servers as part of the automated build process, you can completely control the creation of your staging environment—and hopefully—your production environment as well.
Moving from Continuous Integration (i.e. ongoing, automated builds to staging) to Continuous Delivery (ongoing or one-click deployment to production) is a scary concept to most. But it becomes a lot more feasible when your application follows the patterns outlined here: (1) the application is broken down into manageable microservices, (2) the monolithic database is split up into multiple independent data stores, (3) your application is built to withstand failures, and (4) you can automatically spin up new server instances through code. A key consideration, however, is to make sure that you start implementing Continuous Delivery from day one for new apps because it’s a lot easier to do it when your application is smaller and simpler.
8. Architect as Accountant
On-demand billing is a key component of on-demand computing. Without a doubt this is a great innovation—but it also has its downsides. On the one hand, on-demand billing is wonderful because you only get charged for the resources you use. On the other, it means that the application design choices you make have a direct impact on your monthly bill. Software design has always influenced infrastructure costs, but never with the immediacy and granularity that it does in the cloud. For example, there is a wide range of storage options in the cloud, each with different performance profiles, costs and pricing models. As a cloud architect, you must carefully weigh application requirements against monthly hosting costs. Does the ROI on better performing storage justify the additional cost?

And instead of making these decisions infrequently, as you would when you purchase new equipment in the data center, in the cloud you should be making these decisions all the time. This is because the economics of cloud computing are distinctly different from the economics of the traditional data center. When you own the hardware, your goal is to maximize the utility of the asset during its useful live. This means that infrastructure changes happen infrequently and you end up paying for overcapacity initially to give yourself room to grow. When you rent the hardware, your goal is to maximize performance at a lowest possible monthly cost. This means you can make infrastructure changes continuously and should only pay for the capacity you need right now. The advantage of cloud economics is that you can change or abandon hardware at will since there are no upfront investments that you need to recoup. In some cases, there may be development time involved with switching infrastructure services, so you’ll still need to make changes thoughtfully. But by creating a solid abstraction layer between the application and the underlying infrastructure components you can minimize this cost (and minimize vendor lock-in).
The big challenge in the cloud is that the pricing model for services is complex, highly technical and subject to frequent change (as the cloud market matures, more players are entering the mix and vendors are competing on price). Even answering a simple question like “What will my monthly bill be?” can be very difficult to answer. In order to properly manage and minimize costs in the cloud, the architect needs to take on the additional role of cloud accountant. Since she already understands the business requirements, performance requirements and the technical details that underlie cloud pricing models, the architect is in the best position to manage cloud costs. This means taking responsibility for forecasting hosting costs, assessing infrastructure options, and continuously looking for ways to reduce expenses. Using cloud provider tools like AWS Trusted Advisor can help find potential areas for cost savings, but ultimately you need to optimize for cost based on your individual business needs.
9. Design for Security
Security can no longer be an afterthought in application development—it has to be built-in from the beginning (i.e. secure by design). There’s been too much recent cyber carnage out there for us to continue ignoring the dangers. In a cloud environment, that means starting with a solid understanding of your cloud provider’s security model. Cloud security architecture is very different from the data center security model. For example, you’ll likely rely less on subnetting VLANs and DMZs for security in the cloud, and will probably lean more on your cloud provider’s security service (e.g. Amazon’s Identity and Access Management service) to control security for your application. So before you write a single line of code, read your cloud provider’s security literature, absorb the security model and design your architecture to follow your cloud provider’s recommended best practices. A deep dive into application security is beyond the scope of this paper, but some recommendations are listed below:
- Encrypt data at rest and in transit
- Implement least privileges using your cloud provider’s security service
- Create distinct security groups, e.g. security groups for each application layer or microservice
- Use two-factor authentication, especially for administrative access to your cloud account
- Use security certificates over passwords when possible
- Harden your servers, and store machine images to enforce these policies
- Follow Open Web Application Security Project (OWASP) recommendations for application development
- Monitor your systems closely
Most of the patterns discussed here are designed to promote scalability, availability and performance. Many of them were pioneered by online behemoths like Amazon who deal with huge amounts of traffic every day. So it’s not surprising that some of these techniques, like microservices, database heterogeneity and asynchronicity, create more overhead. They require more coding, necessitate a broader set of technical skills, and can increase overall system complexity. In programming as in life, there’s no such thing as a free lunch. So the question is: Are these design patterns applicable for less highly trafficked sites?
Ultimately, that’s an answer that the architect herself must decide. However, a critical—and often overlooked—business requirement to consider when making these decisions is the speed with which the company needs to change in response to shifts in the business environment. The competitive landscape is changing at an ever increasing rate, driven by never-ending digital disruption. That means that we, as architects, need to design systems that can be changed frequently and rapidly, without compromising quality. The ability to do so, in many industries, means the difference between life and death. Furthermore, if and when management adopts an Agile mindset, we need to be ready to implement it from the technical side.
Interestingly, many of the same practices that enable scalability also enable rapid change. For example, by decomposing functionality into microservices and implementing an event-driven, asynchronous architecture, you promote scalability and make it a heck of a lot easier to deploy more frequent changes without breaking the whole system.
For example, you can deploy only those services that have changed, without deploying the entire application. You no longer have to map out elaborate data deployment strategies because the big monolithic database has been broken down into separate, bite-sized chunks. The deployment itself can then be more easily automated. And, if something does break in production, the application is designed to continue working. So even in the worst-case deployment scenario, the site will continue to run while you resolve the issue.
So, even if you’re not designing for hardcore scalability, a cloud-born architecture makes the release process faster, more robust, and less anxiety-provoking. And if deployment is a less stressfully affair, then you’ll do it more frequently, which means the business can react to change faster.
Conclusion
The world has changed, and is continuing to do so at an increasingly rapid rate. Our application architecture needs to evolve with it, and it has to be structured to withstand the messiness that results from constant change. Fortunately for us, the cloud provides an amazing platform that enables the development of applications that thrive in this new environment. But, we don’t get robustness for free. We have to think differently about how we design applications, and we must embrace the new development paradigms that have risen along with cloud computing. And when we do, it means our own roles as architects must change too. The job is now harder, more complicated, and requires a broader set of skills than ever before. But we wouldn’t have it any other way, would we.